
Introdução
O método abordado é a técnica de compressão LZRW.
- O algoritmo LZRW foi o primeiro de uma série de algoritmos de alta velocidade, sendo conhecido também por “LZRW1” criados a partir de 1990 a 1992 pelo autor Ross N. Williams, do qual tem parte da origem do nome “LZRW” que significa “Lempel-Ziv Ross Williams”.
- A compressão deste algoritmo foi proposta para aumentar o desempenho da classe de algoritmos de compressão baseada em dicionários da família “LZ77”.
- Os tipos de dados que este método utiliza para a sua compressão sem perdas são essencialmente arquivos/ficheiros de texto e binários.
- Utiliza uma hash table
- Tem uma maior velocidade de compressão
- Lê blocos de três caracteres
O Codec abordado neste tema é escolhido por ser uma sequência do algoritmo de compressão da família “LZ77” e está também relacionado com um método comum do algoritmo “LZFG”, que são bastantes reconhecidos no universo das compressões.
O facto de ter desempenho de compressão maior que os seus antecessores foi também uma mais valia para a sua escolha, no ponto de vista em que me despertou o interesse sobre o porquê da sua posição em relação aos outros algoritmos e também o facto de ser o primeiro da sua marcante série.
Áreas de aplicação
As áreas de aplicação em que o Codec é utilizado será feita com base de ficheiros de texto ou binários, de formatos mais comuns como o caso .txt ou .bin. Para isso a norma de codificação mais utilizada para esse efeito será a ANSI ou a UTF-8, caso contrário a aplicação não funcionará correctamente.
Funcionamento do Algoritmo ( Codificação)
Desenvolvido por Ross Williams em 1991, como um simples método baseado em dicionários e rápido, variante do método ”LZ77”, e também relacionado com o método A1 do “LZFG”, a ideia principal para a execução da compressão é encontrar um conjunto de caracteres numa única etapa, utilizando uma hashtable de consulta de índices já codificados . Este é rápido, mas não muito eficiente, uma vez que a expressão encontrada nem sempre é a mais longa.
O método usa toda a memória disponível do look-ahead buffer, de 16 bytes, como um indicador para a leitura da string inicial pelo ponteiro p-src a ser analisado, e codifica a entrada da string em blocos de três caracteres de cada vez. Um bloco é codificado para a zona de memória do search buffer que inicialmente é pequeno, e é de forma aleatória indexado para uma hashtable que vai conter o índice de cada bloco codificado de três caracteres. Então o próximo bloco é lido do mesmo modo e codificado para a zona de memória do search buffer até ao máximo de índices de 4k de memória ou seja 4096 apontadores para blocos de 3 caracteres, e assim por diante. Assim sendo o comprimento máximo da pesquisa de índices nas hashtable para os blocos codificados cresce até 4K e o do look-ahead buffer é de 16 bytes, este último é de comprimento fixo. Estes dois buffers deslizam ao longo do bloco de entrada na memória da esquerda para a direita quando o processo de compressão é terminado. É necessário manter apenas um apontador, p_src, apontando para o início do look-ahead buffer, onde é analisado o início da string a ser codificada e comparada através de uma pesquisa na tabela. O apontador p_src é inicializado a 1, e é incrementado depois de cada bloco codificado.
O funcionamento do algoritmo consiste em 3 Fases:

Figura 1. 1º Fase de pesquisa da string a ser codificada inicialmente no apontador p-src para o primeiro bloco de três caracteres no look-ahead buffer de 16 bytes de cada vez.

Figura 2. 2º Fase de indexamento na hashtable na zona de memória search buffer dos blocos analisados e avanço do look-ahead buffer.

Figura 3. 3º Fase de comparação dos blocos no look-ahead buffer a serem indexados na hashtable do search buffer e codificados pelo seu output.
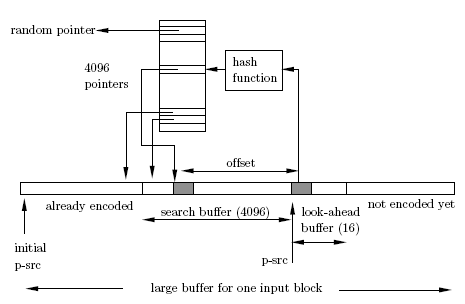
Figura 4. Esquema Geral do Método de codificação LZRW1.
Begin
P_src3 = 1
Int P
look-ahead buffer [max]
search buffer [max]
Chars[max] = Texto (str)
Do for I = 0 to 3
{
look-ahead buffer (16 bytes) = Chars[i] // percorrer texto original
}
While not EOF
{
If (chars existe no dicionário - hash table) {
P_src3 = search buffer [i] // encontra o índice na hash table
P_src3 = p_src3 + 0,5
Output [0] = p_src3 // contém o primeiro elemento do bloco de 3 caracteres
BinaryOutput [16] = Output [0] // converte o elemento existente em binário
}else (chars não existem no dicionário – hash table) {
P_src3 = random (P) // atribui aleatoriamente um índice
search buffer [max] = P_src3 // guarda o índice na hash table
Output [0] = P_src3 // guarda para o output o apontador do primeiro elemento
BinaryOutput [8] = Output [0] // código do caracter na tabela ascii
search buffer ++ // incrementar a hash table
}
P_src3 ++ // incrementar o apontador
}
End
O fundamento principal consiste na procura, numa única etapa da respectiva correspondência usando uma hashtable (array de apontadores). O buffer tem capacidade de 4k e a capacidade de alocação de apontadores é de 4096 (2^12 bits).
De uma forma resumida o método faz uma codificação de bloco a bloco (de três caracteres), onde cada um deles é lido no buffer e codificado sequencialmente comparando índices padrões iguais com os índices padrões que já foram codificados.
Como exemplo temos um texto no input “that_thatch_thaws”. São codificados blocos de três caracteres. Se a expressão não existir o output será o primeiro caracter, e binary output o valor desse caracter será o valor binário na tabela ascii.
Se existir a expressão, o valor do output é igual ao valor do P(ponteiro) + 0,5 , que irá determinar o binary output.

O resultado em binário para a expressão indicada acima seria: t=01110100 h=01101000 a=01100001 t=01110100 espaço=00100000 t=01110100 h=01101000 a=01100001 t=01110100 c=01100011 h=01101000 espaço=00100000 t=01110100 h=01101000 a=01100001 w=01110111 s= 01110011 ou seja:
01110100 01101000 01100001 01110100 00100000 01110100 01101000 01100001 01110100 01100011 01101000 00100000 01110100 01101000 01100001 01110111 01110011 em conjuntos de 8 bits. 8×17=136 bits usados.
Após a codificação a apresentação do resultado final será diferente: t=01110100 h=01101000 a=01100001 t=01110100 espaço=00100000 tha=00000011 00000101 t=01110100 c=01100011 h=01101000 espaço=00000010 00000101 tha=00000011 00000101 w=01110111 s= 01110011 ou seja:
01110100 01101000 01100001 01110100 00100000 00000011 00000101 01110100 01100011 01101000 00000010 00000101 00000011 00000101 01110111 01110011 em conjunto de 8 bits. 8×16=128 bits usados.
O resultado do output será: that4,5tch5,5 4,5ws
Funcionamento do Algoritmo ( Descodificação)
O descodificador é ainda mais simples do que o codificador. É mantido na mesma um p_src usando um apontador da mesma forma do que o codificador. O descodificador lê bloco a bloco a partir da palavra comprimida e usa a sua memória disponível de 16 bits para ler 16 itens no look-ahead buffer. Um item é descodificado literalmente e colocado para o buffer, e sucessivamente p_src é incrementado por 1.
Begin
P_src = 1
Chars[max]
Texto (str)
Do for I = 0 to 16
{
Chars[i] = BinaryOutput[i] // percorrer texto comprimido
}
While not EOF
{
While ( Output existe na hash table)
{
P_src = hash index
Output [0] = BinaryOutput [i]
Texto (str) = Output [0]
}
P_src ++
}
End
A descompressão funciona por base, de encontrar índices padrões dentro do arquivo/ficheiro fonte. A maioria dos arquivos, sejam eles texto ou binário, têm padrões repetidos marcados ou enumerados aleatoriamente por um índice. O que faz é consultar cópias de índices iguais para o arquivo descompactado até formar de novo a string.
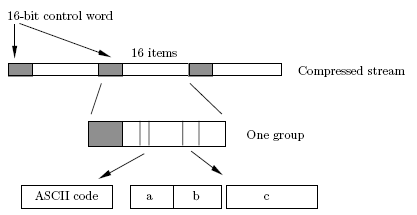
Para determinar a descompressão o método é inverso da compressão. O conjunto que forma o output da codificação será interpretado por grupos de 16 itens (bits), que constituem a expressão binária, onde é convertida para a letra correspondente ao índice que o representa através do ponteiro. De forma simples, o conjunto de 8 ou 16 bits é descomprimido para a notação textual, onde se irá formar novamente a string “that_thatch_thaws”.
Forma normal da compressão: that4,5tch5,5 4,5ws
01110100=t 01101000=h 01100001=a 01110100=t 00100000=espaço 00000011 00000101=tha 01110100=t 01100011=c 01101000=h 00000010 00000101=espaço 00000011 00000101=tha 01110111=w 01110011=s em conjunto de 8 bits.
Forma normal após a descompressão: that_thatch_thaws
Implementação do Algoritmo “LZRW1”
Os métodos testados são o LZRW1 juntamente com o LZO e o Deflate.
O algoritmo de compressão sem perdas de dados conhecido como Deflate é uma combinação de diversas tecnologias de compressão de dados usada nos arquivos do padrão ZIP e nos utilitários do padrão G-Zip.
O algoritmo de compressão LZO é um método de compressão do formato 7z no programa 7-Zip, bastante utilizado na modelagem de dicionários. Este método é também muito usado na compressão de dados através da rede. Utiliza uma biblioteca de compressão e descompressão de dados em tempo real.
Possui resultados tão bons quanto o algoritmo de compressão LZW, sendo um algoritmo de domínio público, enquanto o LZW é patente da Unisys.
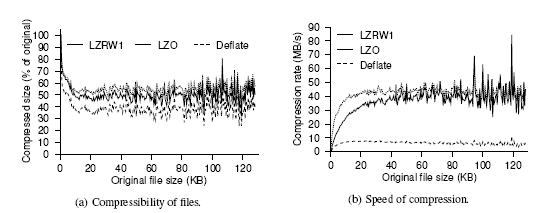
- a) representa o tamanho da compressão do ficheiro em percentagem em relação ao ficheiro original para um dado tamanho do ficheiro em Kbytes.
- b) representa a velocidade de compressão dos três métodos, a taxa de compressão em MB/s para um dado tamanho do ficheiro a comprimir em Kbytes.
Em ambos os gráficos o LZRW1 é um algoritmo capaz de rivalizar com os outros métodos, uma vez que possui uma boa percentagem de compressão do ficheiro original e também possui uma velocidade superior para ficheiros de tamanho superiores a 80 Kbytes. O algoritmo LZO é aquele que por sua vez faz maior concorrência ao LZRW1 mostrando também boas qualidades e referências, enquanto o algoritmo Deflate é o menos eficiente em ambos os casos.
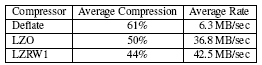
Nesta tabela de resultados podemos ver a média de compressão do ficheiro original e a taxa de velocidade a que corresponde cada método. Pode não parecer mas o método de compressão LZRW1 é mais eficiente do que ambos os outros porque embora tendo a média mais baixa de compressão, é aquele que preza com maior taxa de velocidade de compressão sendo a sua principal característica de maior poder de compressão. O método LZO possui também bons resultados, bem próximos do LZRW1 embora o Deflate, ser o método que comprime mais em média é um algoritmo bastante mais demorado não sendo tão eficiente.
Comparação do método de compressão (LZRW1-Jeff Connelly versão melhorada de 1998) baseado em dicionários, com os métodos mais recentes e mais conhecidos no mundo actual da compressão de textos como são exemplos os programas: o WinRAR (versão 3.61 de 2006), o WinZip (versão 12 de 2008) e o 7-Zip de compressão LZMA (versão 4.65 de 2009).
Tamanho original do ficheiro = 2.01 Kbytes
Compressão:
Método LZRW1: Tamanho do ficheiro comprimido = 0.312Kb
Rácio Verificado=2.01/0.312 (kbytes) = 6.43:1
WinRAR: Tamanho do ficheiro comprimido = 0.137Kb
Rácio Verificado =2.01/0.137 (kbytes) = 14.8:1
WinZip: Tamanho do ficheiro comprimido = 0.207Kb
Rácio Verificado =2.01/0.207 (kbytes) = 9.7:1
7-Zip: Tamanho do ficheiro comprimido = 0.169Kb
Rácio Verificado =2.01/0.169 (kbytes) = 11.9:1
Com os cálculos efectuados para este teste, através da fórmula do rácio de compressão podemos tirar conclusões absolutas no domínio das compressões sem perdas para os ficheiros de texto obtidos. Assim sendo o resultado do rácio comprova o domínio do programa WinRAR que é o programa mais bem sucedido e possivelmente o mais utilizado, que lidera em relação aos outros métodos de compressão aqui testados. Podemos também tirar partido desta conclusão para salientar o progresso que tem ocorrido nas compressões de dados nos últimos anos, desde que foi criado o LZRW1 em 1991 com algumas evoluções até 1998, e os anos que ocorrem actualmente com o lançamento dos últimos algoritmos para a compressão até 2009, ou seja, para um tamanho fixo de um ficheiro original comprimido por um algoritmo datado de 1998 (LZRW1 – versão melhorada) até 2009 (7-Zip versão de 2009), cerca de 10 anos depois houve uma evolução de aproximadamente 3 vezes mais de compressão e também de rapidez. Nota: a eficiência de alguns programas mais recentes, como a versão do WinZip e 7-Zip pode ser melhorado nos possíveis resultados finais, em casos de ficheiros ou arquivos de grandes dimensões. Para este caso foi uma amostra de teste significativo.
Vantagens e Desvantagens do método LZRW1:
Este algoritmo permite uma maior taxa de velocidade (MB/s) de compressão e de descompressão.
Evidencia-se por ser um algoritmo algo simples e com bom desempenho.
Nem sempre a pesquisa efectuada retorna a sequência mais longa presente no searchbuffer, isto tem como consequência uma menor eficiência.
Trabalho desenvolvido no âmbito da disciplina de Multimédia II da Licenciatura em Engenharia Informática, lecionada pelo Prof. Doutor Nuno Magalhães Ribeiro da Faculdade de Ciência e Tecnologia da UFP.
Texto da autoria de José Cunha (15544) e revisto por Nuno Magalhães Ribeiro.
Código java da autoria de José Cunha (15544).
Site planeado, desenhado, desenvolvido e programado por Daniel Dias Lima Mendes, Diogo Emanuel Lamas e Silva, Nelson José Santos Almeida no âmbito do Projeto de final de Licenciatura realizado na Unidade Curricular de Laboratório de Projeto Integrado sob a orientação técnica do Prof. Doutor Nuno Magalhães Ribeiro.