
Introdução
LZSS é uma variante do método LZ77.
O algoritmo LZ77 foi inventado em 1977 por Abraham Lempel e Jacob Ziv, mas em 1982 James Storer e Thomas Szymanski introduziram uma, pequena mas eficaz, alteração a este algoritmo melhorando o rácio de compressão.
O método de compressão LZSS é um método de compressão sem perdas, codificação de entropia, que se baseia num dicionário para realizar a compressão do Input original.
O funcionamento do dicionário nesta e a maneira como o algoritmo aproveita a utilização do mesmo para realizar a compressão será abordada mais adiante.
O LZ77, será abordado, porque é o antecessor do LZSS existindo, assim, pontos comuns entre as duas técnicas.
Áreas de aplicação
A técnica LZSS é usada em alguns dos mais populares compressores, entre os quais se encontram PKZip, ARJ, LHArc, ZOO, entre outros.
Cada um destes compressores implementa esta técnica de maneira diferente, dependendo, na maioria dos casos, no comprimento do ponteiro, no tamanho da janela, e na maneira como a janela se move.
A técnica LZSS pode também ser combinada com outros métodos de codificação de entropia, por exemplo Huffman ou Shannon-Fano.
LZSS e Huffman são usados em conjunto no compressor ARJ, e a combinação entre Shannon-Fano e LZSS pode ser encontrada nas versões iniciais do PKZip, embora versões mais recentes também usem codificação de Huffman.
Enquadramento do Algoritmo LZSS
O algoritmo LZ77 foi inventado em 1977 por Abraham Lempel and Jacob Ziv, no entanto, em 1982, James Storer e Thomas Szymanski introduziram uma pequena mas eficaz alteração ao algoritmo LZ77 com a finalidade de melhorar a compressão obtida. Esta versão modificada, e muito utilizada, do algoritmo LZ77 denomina-se por LZSS.
O Dicionário
O dicionário usado por ambos os métodos não é um dicionário externo que contém uma listagem de todos os símbolos e combinações possíveis entre eles. Ao invés disso, o dicionário, é uma “janela deslizante”, sliding window, que consiste em duas partes, um buffer de busca, ou dicionário, que contém uma parte do input já codificado, N, e um look-ahead buffer que contém a próxima parte do input a ser codificado, N.
Quanto maior for N, mais tempo demora a pesquisar todo o dicionário à procura de uma correspondência e consequentemente mais bits serão utilizados para armazenar o “desvio”, offset, no dicionário.
Tipicamente os dicionários contêm uma certa quantidade de símbolos que podem ser representados por potências de 2. Um dicionário quem contenha 432 símbolos necessitaria de 9 bits para representar todos os offsets possíveis.
Uma vez que o símbolo N+1, é processado e adicionado ao dicionário, o primeiro símbolo é removido, não do dicionário mas da “janela”. Assim sendo, novos símbolos originam que número igual de símbolos que já constem na “janela” sejam “descartados”, slide out, para que os novos símbolos ocupem o seu lugar.
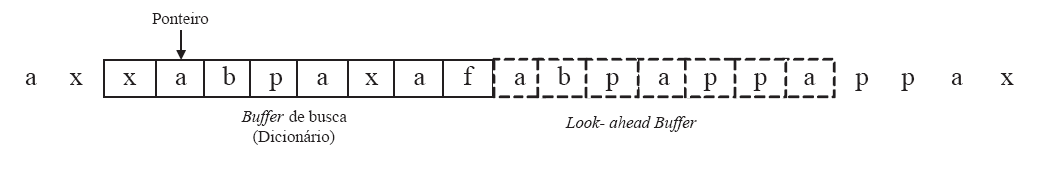
Figura 1 – Exemplo da sliding window e lookahead buffer.
O Método LZ77
O algoritmo LZ77 é um método de dicionário adaptativo. Os métodos de compressão baseados em dicionários adaptativos são caracterizados principalmente por:
- Não necessitarem de conhecer a estatística dos dados a comprimir;
- Não usarem códigos de comprimento variável;
- Utilizarem como Input, uma sequência de símbolos de comprimento variável.
No método LZ77, o dicionário é simplesmente uma parte da sequência previamente codificada, examinando-a através de uma “janela deslizante”, tal como foi explicado anteriormente.
Para codificar a sequência no look-ahead buffer, o codificador move o ponteiro de busca para trás através do buffer de busca até encontrar o primeiro símbolo do look-ahead buffer. A codificação é feita utilizando uma “tupla” (oi, mi, ci), onde (oi) é o offset, a distância do ponteiro até o look-ahead buffer. (mi) é o match, ou seja, é o número de símbolos consecutivos no dicionário que são idênticos aos símbolos consecutivos no look-ahead buffer, iniciando com o primeiro símbolo referenciado no ponteiro, ou seja, o match especifica o comprimento da sequência de símbolos repetidos. O LZ77 ainda usa um terceiro elemento, (ci), que é o primeiro símbolo do look-ahead buffer subsequente à frase ao offset e ao match. No caso de não ser encontrada uma sequência no look-ahead buffer, os valores do offset e do match são iguais a 0, e o terceiro valor é o código do próprio símbolo.
O Método LZSS
O método LZSS, é uma variante do LZ77 que procura evitar alguns dos problemas presentes no LZ77.
Existem três principais mudanças no modo como o algoritmo trabalha. A primeira é no modo que a janela deslizante é mantida. A segunda alteração encontra uma saída para reduzir o problema com a “tupla” do algoritmo de compressão do LZ77. A terceira é a utilização de buffer circular.
Analisando a primeira alteração verifica-se que no LZSS as frases que entram na “janela deslizante” continuam a ser armazenadas como um simples blocos de texto contínuo, tal como no LZ77, contudo cria uma estrutura de dados adicional que melhora a organização da frase, uma estrutura em árvore de busca binária.
Analisando a segunda alteração, o LZSS usa um bit simples como prefixo, em vez de uma “tupla” de 3 bytes. Quando a saída é apenas um caractér, o prefixo chamado de flag tem o valor de 0, assim a saída é apenas o flag (fi) e o caractér (ci).
Nota: O funcionamento das flags será explicado posteriormente.
LZ77 Vs LZSS
Para melhor entender as diferenças do LZSS para o LZ77, os exemplos seguintes utilizam o mesmo input, assim sendo podemos verificar o uso de flags por parte do método LZSS e o output gerado por cada código.

Figura 2 – Exemplo de codificação usando o método LZ77.

Figura 3 – Exemplo de codificação usando o método LZSS.
Embora neste caso o rácio de compressão de ambos os métodos ser semelhante, para inputs maiores e com mais repetições a diferença entre os rácios de compressão torna-se mais notória, sendo o método LZSS o que oferece sempre melhor rácio de compressão.
O Algoritmo LZSS
O codificador LZSS utiliza uma “janela deslizante” para codificar o input. Utilizando o dicionário o algoritmo LZSS efectua uma pesquisa no mesmo procurando correspondências entre o símbolo a codificar e as entradas já presentes no dicionário. Para tal é utilizada, por exemplo, uma árvore binária de pesquisa ou uma hashtable. O output do algoritmo consiste num byte “literal” ou num par (offset, tamanho). Um byte “literal” é o próprio byte copiado para o output, um par (offset, tamanho) significa que se recuarmos uma distância de “offset” nos dados de entrada, input, encontraremos uma correspondência de “tamanho” bytes. Para haver uma distinção entre bytes literais e pares Storer e Szymanski introduziram a utilização de flags. O uso de flags no output veio ajudar na distinção dos dois casos, utilizando uma flag “0” se o próximo byte for um byte “literal” ou uma flag “1” se o próximo byte for um par (offset, tamanho).
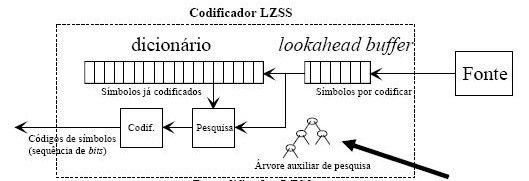
Figura 2 – Diagrama de blocos do codificador LZSS
Contudo o output ocuparia mais espaço que o input original. Para que tal não aconteça é necessário impor algumas restrições.
É necessário restringir o tamanho da flag utilizada. Como uma flag apenas será utilizada como controle, para distinção de bytes, será usado apenas 1 bit para cada flag.
A segunda restrição imposta será limitar os bits usados para os pares (offset, tamanho). Assim sendo limitaremos o tamanho do dicionário a utilizar, limitando o “offset”, e o tamanho do lookahead buffer, limitando “tamanho”.
Mesmo utilizando “tamanho” de um certo tamanho poderemos ter que limitar o comprimento das correspondências porque levaria a que o par (offset, tamanho) ocupasse muitos bits. Alterando o comprimento mínimo das correspondências podemos escolher codificar bytes como sendo “literais” mesmo que haja uma correspondência algures, evitando a codificação de 1 só byte como um par, o que ocuparia mais bits do que se for codificado como sendo um byte “literal”.
Pseudo-Código
Step 1 – Começar o inicio da codificação na primeira posição do Input;
Step 2 – Encontrar a correspondência máxima na “janela deslizante” para a string presente no look-ahead buffer:
Step 2a – P = ponteiro para a correspondência (offset);
Step 2b – L = tamanho da correspondência (tamanho);
Step 3 – L >= MIN_LENGTH?
Step 3a – Sim: escrever o par (offset, tamanho) e mover o look-ahead buffer L caracteres para a frente;
Step 3b – Não: escrever o byte literal, ou seja, escrever o primeiro caractér que se encontra na primeira posição do look-ahead buffer e move-lo um caractér para a frente;
Step 4 – Se houver mais caracteres a codificar voltar ao Step2.
Exemplo
Input Data = “ABCDABCA”
- Começando no primeiro byte -> “A”
Este byte já se encontra no dicionário? Não
Então codificamos o byte como um byte literal com a respectiva flag a “0”
Output data = 0 “A”
- O próximo byte é “B”
Este byte já se encontra no dicionário? Não
Então codificamos o byte como um byte literal com a respective flag a “0”
Output data = 0 “A” 0 “B”
- O próximo byte é “C”
Este byte já se encontra no dicionário? Não
Então codificamos o byte como um byte literal com a respectiva flag a “0”
Output data = 0 “A” 0 “B” 0 “C”
- O próximo byte é “D”
Este byte já se encontra no dicionário? Não
Então codificamos o byte como um byte literal com a respectiva flag a “0”
Output data = 0 “A” 0 “B” 0 “C” 0 “D”
- O próximo byte é “A”
Este byte já se encontra no dicionário? Sim
Então
Procuramos a ocorrência anterior deste mesmo byte -> offset = 4
Quantos bytes previamente codificados são iguais aos que estão na “janela” para serem codificados -> tamanho = 3 bytes (“ABC”)
Codificamos o byte como um par (offset, tamanho) com a respective flag a “1” e saltamos N + tamanho elementos do input a codificar. ( “1” (4, 3) e N <- N+3 )
Output data = 0 “A” 0 “B” 0 “C” 0 “D” 1 4 3
- O próximo byte é “A”
Este byte já se encontra no dicionário? Sim
Então
Procuramos a ocorrência anterior deste mesmo byte -> offset = 3
Quantos bytes previamente codificados são iguais aos que estão na “janela” para serem codificados -> tamanho = 1 byte (“A”)
Codificamos o byte como um par (offset, tamanho) com a respective flag a “1” e saltamos N + tamanho elementos do input a codificar. ( “1” (3, 1) e N <- N+1 )
Contudo, como vimos anteriormente, se impusermos um limite mínimo de correspondência podemos codificar este byte como um byte literal, aumentando o rácio de compressão.
Output data = 0 “A” 0 “B” 0 “C” 0 “D” 1 (4, 3) 0 “A”
Rácio de compressão = (8bytes * 8) / 62 = 1,032:1
O Algoritmo de descompressão
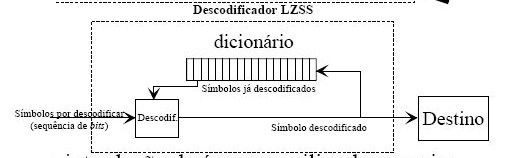
Figura 3 – Diagrama de Blocos do Descodificador LZSS
O processo de descodificação LZSS é bastante mais simples e rápido que o processo de codificação.
O processo de codificação necessita que o dicionário seja pesquisado várias vezes de maneira a procurar correspondências para o input a codificar. Pelo contrario o processo de descodificação apenas necessita que se encontre o offset presente no par (offset, tamanho) e copiar o número especifico de símbolos lá presentes, não é necessária nenhuma pesquisa, diminuindo a complexidade e tempo de execução do algoritmo.
Pseudo-Código
Step 1 – Inicialização do dicionário com um valor específico.
Step 2 – Ler a flag.
Step 3 – Se a flag indicar uma string, do input, previamente codificada:
Step 3a – Ler o par (offset, tamanho), e de seguida copiar o número específico de símbolos do dicionário para o output.
Step 3b – Senão, ler o próximo caractér e escrever no output.
Step 4 – Desloque uma cópia dos símbolos escritos no output para o dicionário.
Step 5 – Repetir do Step 2 em diante, até todo o input ter sido descodificado.
Exemplo
Input data = 0 “A” 0 “B” 0 “C” 0 “D” 1 (4, 3) 0 “A”
- Flag = 0
Byte = literal “A”
Output/Dicionário = A
- Flag = 0
Byte = literal “B”
Output/Dicionário = AB
- Flag = 0
Byte = literal “C”
Output/Dicionário = ABC
- Flag = 0
Byte = literal “D”
Output/Dicionário = ABCD
- Flag = 1
Byte = par (offset, tamanho)
- Offset = 4 “A”
- Tamanho = 3 “ABC”
Output/Dicionário = ABCDABC
- Flag = 0
Byte = literal “A”
Output/Dicionário = ABCDABCA
Implementação
/************************************************************** LZSS.C -- A Data Compression Program (tab = 4 spaces) *************************************************************** 4/6/1989 Haruhiko Okumura Use, distribute, and modify this program freely. Please send me your improved versions. PC-VAN SCIENCE NIFTY-Serve PAF01022 CompuServe 74050,1022 **************************************************************/
Código
LZSSConclusão
Podemos chegar a conclusão que o método de compressão LZSS é mais eficaz que o método LZ77.
Através de uma comparação de rácios de compressão atingidos por ambos os métodos, para o mesmo input, verificamos que o método LZSS realiza a compressão de dados mais eficazmente, ou seja tem um maior rácio de compressão.
O primeiro exemplo apresentado neste trabalho é um input algo reduzido pelo que nem chega a haver compressão efectiva por parte de ambos os métodos, mas sempre com maior rácio para o método LZSS. No segundo exemplo apresentado já se verifica uma compressão, ainda que ligeira, por parte do método LZSS.
Quanto maior for o input e mais repetições houver, maior será a compressão efectuada pelo método LZSS, pois à medida que nos aproximamos do final do input já haverá mais entradas no dicionário tornando assim diferença entre os rácios de compressão mais notória. Isto também é verdade para o método LZ77, mas como utiliza sempre tuplas de 3 bytes para codificar o input o rácio de compressão será menor que o rácio do método LZSS pois este utiliza no máximo, caso de um par(offset, tamanho), 2 bytes e 1 bit para realizar a compressão.
Ambos os métodos fazem uso de um dicionário e de uma “janela flutuante”, sendo as principais diferenças, e o que torna o método LZSS mais eficaz, a utilização de flags e a compressão de bytes que não existem no dicionário, ou que existem mas não obedecem ao critério de correspondência mínima, como “literais”, usando menos bytes para realizar a compressão do input.
Bibliografia
- http://oldwww.rasip.fer.hr/research/compress/algorithms/fund/lz/lz77.html
- http://oldwww.rasip.fer.hr/research/compress/algorithms/fund/lz/lzss.html
- http://michael.dipperstein.com/lzss/
- http://www.hiddensoft.com/code/
- http://www.cs.biu.ac.il/~wiseman/dsj2007.pdf
- http://garbo.uwasa.fi/pub/pc/doc-soft/lz-comp.txt
- http://sac-ftp.externet.hu/pack11.html
- http://www.cpgei.cefetpr.br/~zaqueu/dissertacao.pdf
- http://www.cc.isel.ipl.pt/Pessoais/DavidCoutinho/etc/TMC%20sessao8%20Codif_Lempel_Ziv.pdf
Trabalho desenvolvido no âmbito da disciplina de Multimédia II da Licenciatura em Engenharia Informática, lecionada pelo Prof. Doutor Nuno Magalhães Ribeiro da Faculdade de Ciência e Tecnologia da UFP.
Texto da autoria de Nuno Silva (14632) e revisto por Nuno Magalhães Ribeiro.
Código java da autoria de Nuno Silva (14632).
Site planeado, desenhado, desenvolvido e programado por Daniel Dias Lima Mendes, Diogo Emanuel Lamas e Silva, Nelson José Santos Almeida no âmbito do Projeto de final de Licenciatura realizado na Unidade Curricular de Laboratório de Projeto Integrado sob a orientação técnica do Prof. Doutor Nuno Magalhães Ribeiro.