
Introdução
Este método foi desenvolvido por Hidetoshi Yokoo em 1991, um professor Doutor de nacionalidade Japonesa, docente na Universidade de Gunma no Japão. Fez a sua formação na Universidade de Tokyo e actualmente desenvolve pesquisas na área da compressão de dados, nomeadamente desenvolvimento de algoritmos adaptativos para tipos de compressão sem perdas e aplicações da compressão de dados em ciências da computação em geral.
O Repetition Finder corre em tempo real e a memoria necessária depende, unicamente, do tamanho do alfabeto a codificar,
Este é um método pouco explorado e pouco eficiente que é utilizado, essencialmente, na compressão de texto. Por estas razões não deve ser usado como um método prático e “maduro” de compressão, mas sim como um primeiro passo para uma nova pesquisa ou desenvolvimento de um melhoramento do mesmo.
Na literatura utilizada para este trabalho, o Repetition Finder é descrito com sendo um método de compressão sem perdas e do tipo baseada em dicionários.
Áreas de aplicação
Sendo este algoritmo, como já referido anteriormente, um melhoramente à codificação de Huffman Adaptivo, as áreas de aplicação são, como é óbvio, partilhadas. A codificação Huffman é das mais populares no meio computacional, tem uma vasta área de aplicação, estando presente em grande parte das aplicações no nosso computador.
É usado desde a codificação de textos e imagens até o lugar de método auxiliar para outros métodos de compressão, como por exemplo, o formato JPEG para codificação de imagens, o formato MP3 para codificação de áudio, entre outros.
O algoritmo do “Repetition Finder”
Codificação
Embora esteja inserido na codificação baseada em dicionários, este método utiliza, em vez de um dicionário, um array bidimensional de comprimento fixo para detectar ocorrências prévias de strings do texto a ser codificado, array esse que chamaremos de REP. REP tem como tamanho, o quadrado do tamanho do alfabeto do texto em questão. Por exemplo, tendo um alfabeto A de tamanho N, REP = |N| x |N|, ou seja, uma matriz com N colunas e N linhas, correspondendo a cada índice um carácter do alfabeto.
O Repetition Finder é, essencialmente, um melhoramento ao método Huffman Adaptativo (codificação estatística) e alterna entre dois modos: o modo normal e o modo repetição onde os dados são codificados em dois algoritmos distintos, um para cada modo. O método começa no modo normal, onde codifica símbolos usando o Huffman Adaptativo, quando encontra repetições de strings passa para o modo repetição, onde lança uma flag (a flag tem de ser um símbolo que não esteja presente no alfabeto) seguido do tamanho da string repetida.
No modo repetição, que é onde este método é aplicado, o algoritmo calcula para cada símbolo de entrada um valor de Yi = i – REP[ Xi-1 , Xi ] e actualiza REP[ Xi-1 , Xi ] = i.
De seguida está uma explicação do cálculo do valor de Yi.

Pseudocodigo do algoritmo de codificação:
[Criar uma array para armazenar os símbolos de entrada]
Do for i=0 to N-1
A[i] = nextInputSymbol;
[Inicializar a matriz REP a zeros]
M=N
Do for i=0 to N-1
Do for i=0 to M-1
REP [M, N] = 0
[Calcular Yi]
Do for i=0 to N-1
Yi = i – REP[ Ai-1 , Ai ]
[Actualizar o conteúdo de REP]
REP[ Ai-1 , Ai ] = i
[Retorna flag seguida do tamanho da string repetida]
repetiton={!} + Yi
Return repetition;
Descodificação
O descodificador recebe e descodifica os símbolos no modo normal (Huffman Adaptavito) até ao índice onde ocorre a primeira repetição, enquanto actualiza o array REP e calcula os valores de Y. Quanto encontra uma flag, é descodificada a string com o tamanho de i-Yi e descobre a que valor isso corresponde no array REP.
Como i tem um valor e Yi é a distância de i à sua cópia, o descodificador sabe que a repetição começa da posição i-Yi. Ele percorre a matriz REP à procura do valor 3 e assim sucessivamente.
Exemplo de aplicação
Para exemplificar o funcionamento do codificador, vamos considerar como input um conjunto de caracteres dado por “X A B C D E Y A B C D E Z”, indexado de ZERO (0) a DOZE (12).
Codificação
Como vimos anteriormente, este algoritmo é aplicado na codificação/descodificação de textos. Para podermos perceber melhor o funcionamento do mesmo nada melhor que um exemplo prático, para isso vamos considerar um input A = {XABCDEYABCDEZ}.
Para começar teremos o input, indexada por i:

Os valores de Y, nos casos onde não existe repetição, é dado por Yi = i. Para os casos onde existe repetição é dado por Yi = i – REP[ Xi-1 , Xi ], como é exemplificado de seguida:
Para i = 8:
Y8 = 8 – 2 = 6
Para i = 10:
Y9 = 9 – 3 = 6
Para i = 11:
Y10 = 10 – 4 = 6
Para i = 12:
Y11 = 11 – 6 = 6
Tabela final com valores do índice i, seus respectivos valores Y e pares de caracteres que representam o carácter precedente a i seguido do carácter em i. O cálculo de Y é feito de acordo com a Ilustração 1 anteriormente mostrada.

Para a matriz REP, começaríamos com os índices todos a zeros e à medida que os cálculos de Yi vão sendo calculados o algoritmo actualiza a tabela de índices REP de maneira a guardar o índice da última ocorrência do par de caracteres a ser tratado, para depois ser usada da descodificação:
No passo referente a i=7, teríamos a matriz desta forma:
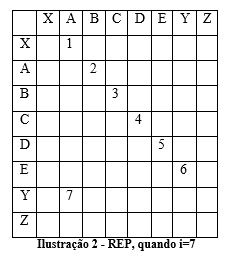
No passo seguinte, quando i=8, a matriz sofria uma alteração porque volta a ocorrer o par de caracteres [AB], sendo o valor de Yi calculado e a posição da nova de [AB] armazenada em REP:
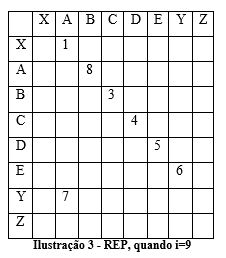
A lógica é sempre a mesma, até não haver mais símbolos para tratar. Neste exemplo teríamos uma matriz REP final (último passo, quando i=12) da seguinte forma:
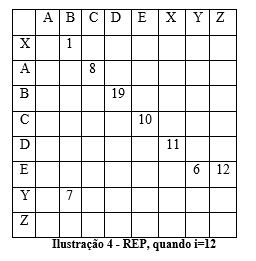
Concluindo:
- Os primeiros nove caracteres são codificados no modo normal, visto que o codificador detecta as repetições tardiamente, logo a primeira repetição de cada bloco repetitivo é codificado normalmente em Huffman Adaptativo;
- Para os caracteres tratados em modo repetitivo (CDE), é lançado o carácter especial (!) seguido do tamanho da string repetida;
- O último carácter como é a primeira vez que ocorre é codificado em modo normal também.
O código Huffman Adaptativo não é aqui tratado, por isso o output para símbolos codificados em modo normal é mantido no formato original, ou seja, os caracteres do input: XABCDEYAB!3Z
(código Huffman Adaptativo para: “XABCDEYAB”. [CDE] codificado como “!3”. Código Huffman Adaptativo apra “Z”)
Implementação do algoritmo “Repetiton Finder”
A implementação deste método, implica o desenvolvimento de código para os dois modos que constituem o Repetition Finder: Normal e Repetição.
No modo normal foi necessário desenvolver o Huffman Adaptativo e no modo Repetição o algoritmo Repetition Finder propriamente. Nos parágrafos seguintes é descrito os aspectos inerentes a cada um dos modos.
No modo normal definimos a estrutura de dados descrita de seguida, tendo como referência de que uma Árvore Huffman é uma MaxHeap em que todos os nós filhos têm um peso menor que os dos Nodos pai.
Uma classe Nodo que terá os seguintes campos: charNode que será a representação inteira do carácter de input, weightNode que é o peso (frequência) do carácter associado, huffCode que contém o código Huffman final do carácter e três referencias para a própria classe, um para o Nodo direito, outro para o esquerdo e finalmente um para o Nodo pai.
Teremos também a classe DyanmicHuffman que é a representação da árvore Huffman e que contem a classe Main. Esta classe tem um campo root que representa o Nodo raiz da árvore. É aqui que os métodos para o tratamento da árvore são implementados.
No modo repetição, temos um array bidimensional (matriz) para armazenar os índices das ocorrências dos símbolos de input (rep[][]) e um array unidimensional para armazenar as diferencias entre um símbolo e uma ocorrência previa desse mesmo símbolo (y[]).
Para a implementação deste algoritmo, escolhemos a linguagem de programação Orientada a Objectos (OO) JAVA, usando o NetBeans 6.8 como ambiente de desenvolvimento.
O executável (RepetitionFinderCodec.jar) referente ao Codec Repetition Finder encontra-se na pasta “RepetitionFinderJAR” juntamente com o ficheiro de texto a ser codificado.
O input é lido do ficheiro de texto “Readme.txt” que, por predefinição, encontra-se na pasta acima referida (RepetitionFinderJAR). O output (codificação) é escrito para um ficheiro que será criado também na mesma pasta e chama-se “ReadmeCodified.txt”. O utilizador se quiser alterar o texto a ser codificado terá de alterar o ficheiro “Readme.txt”.
O Projecto JAVA (código) e o relatório encontram-se na pasta “Projecto JAVA e Relatório”.
Para correr a codificação Huffman Adaptativa deve corremos a classe DynamicHuffmanMain.java presente na package HuffmanAdaptativo.
De realçar que a codificação Huffman Adaptativa não está completa, faltando alguns aspectos referentes à implementação, logo não produz, por enquanto, qualquer código binário.
Esquema do projecto JAVA (NetBeans IDE 6.8):
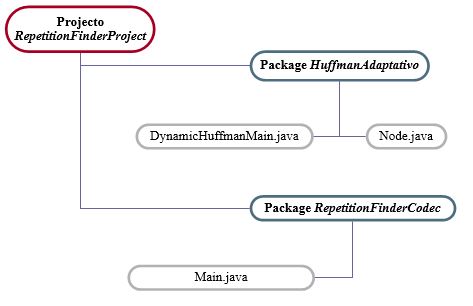
Em anexo a este documento encontra-se o projecto JAVA onde é feita a implementação de ambos os modos, que é constituído por duas packages: RepetitionFinderCodec e HuffmanAdaptatido.
Conclusão
Este método não é muito eficiente porque detecta as repetições tardiamente, logo a sua performance é fraca. Para obter uma eficiência máxima deste algoritmo as entradas na matriz REP deverão ser de 2 bytes, desta forma o i pode conter ate 64K. Para um alfabeto de 256 símbolos por exemplo, o tamanho de REP seria de 2562 x 2 = 128 KB. Para valores acima disto a matriz REP seria demasiadamente grande, logo o algoritmo tornar-se-ia menos eficiente.
No exemplo acima tratado a compressão é mínima, pois na entrada tínhamos 13 caracteres e no final teríamos 12 símbolos (10 da compressão Huffman e 2 do Repetition Finder (!3) ). Torna-se óbvio que, se o tamanho da repetição fosse muito maior ou se houvesse mais repetições ao longo do input, o ganho seria maior.
Trabalho desenvolvido no âmbito da disciplina de Multimédia II da Licenciatura em Engenharia Informática, lecionada pelo Prof. Doutor Nuno Magalhães Ribeiro da Faculdade de Ciência e Tecnologia da UFP.
Texto da autoria de Ricardo Alcântara (15933) e António Mendes (15926) e revisto por Nuno Magalhães Ribeiro.
Site planeado, desenhado, desenvolvido e programado por Daniel Dias Lima Mendes, Diogo Emanuel Lamas e Silva, Nelson José Santos Almeida no âmbito do Projeto de final de Licenciatura realizado na Unidade Curricular de Laboratório de Projeto Integrado sob a orientação técnica do Prof. Doutor Nuno Magalhães Ribeiro.