
Introdução
O algoritmo LZ77 foi criado por Abraham Lempel e Jacob Ziv em 1977. Este algoritmo era inicialmente denominado de LZ1 devido ao facto de os seus autores também terem publicado o LZ2 (LZ78) no ano seguinte.
O algoritmo a ser abordado neste artigo é o LZ77 que utiliza uma técnica de codificação de entropia (sem perdas de significado) baseada em dicionários.
Este codec baseia-se na utilização das partes que já foram lidas de um ficheiro como um dicionário, substituindo as próximas ocorrências das mesmas sequências de símbolos pela posição da sua última ocorrência. Para limitar o espaço de busca e de endereçamento necessário, as ocorrências anteriores são limitadas por uma janela deslizante (sliding window). O tamanho das janelas é fixo e predefinido e desliza sobre os símbolos lidos do ficheiro O codificador trata a porção de dados que “cabem” na janela, dividindo-a em duas partes: a parte esquerda que se refere à procura para trás
(histórico), ou seja, os dados que já foram codificados e que é o dicionário propriamente dito, e a parte da direita, parte de procura para a frente, que contém os dados por codificar.
Devido a este algoritmo não ser patenteado é amplamente utilizado, em programas, como o algoritmo DEFLATE que combina LZ77 e Código de Huffman para comprimir dados e formatos tais como: ZIP, GZIP, PKZIP e PNG.
Áreas de aplicação
Este codec é utilizado em programas e formatos tais como: ZIP, GZIP, PKZIP e PNG. Este codec obtém melhor desempenho em ficheiros que contenham grandes quantidades de texto e em que certas palavras ou encadeamento de letras é mais comum, podendo assim fazer uma substituição de um número, por vezes elevado, de símbolos por apenas um token que guarde a mesma informação gastando menor número de bits.
O algoritmo do LZ77
Numa codificação baseada em dicionários, como é o caso do LZ77, o modelo é constituído por uma sequência de símbolos, a informação está associada a sequências de símbolos e não a símbolos isolados do alfabeto. Este método usa o princípio de substituir sequências de símbolos num ficheiro por um apontador para uma ocorrência prévia no mesmo ficheiro. Esta técnica de compressão usa códigos de comprimento fixo e não necessita de conhecer a estatística dos dados a comprimir.
Codificação
A figura seguinte exemplifica o método de codificação LZ77, ilustrando a separação entre os dados codificados e por codificar:
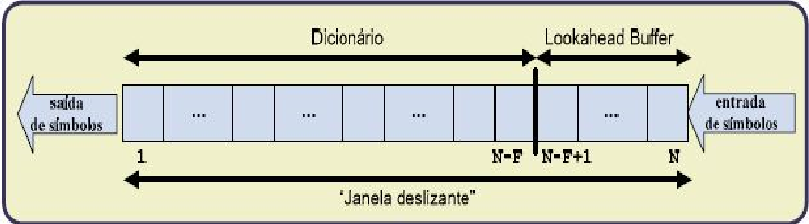
N – Tamanho da janela deslizante;
N-F – Tamanho do dicionário, que contém os símbolos já codificados;
F – Tamanho do Lookahead Buffer, que contém os símbolos lidos ainda por codificar.
O algoritmo LZ77 procura sequências repetidas, comparando o conteúdo do Lookahead Buffer com uma sequência de caracteres existente no dicionário, tentando encontrar a maior sequência igual. A sequência encontrada é substituída por um token (P, T, C), onde P é a posição de distância do primeiro símbolo da sequência em relação ao Lookahead Buffer, T é o comprimento da sequência de símbolos encontrada e C é o primeiro símbolo do Lookahead Buffer que não coincide com a sequência encontrada.
Inicialmente tanto o Lookahead Buffer como o dicionário estão vazios e, ao longo do funcionamento do algoritmo, os dados vão deslizando pela janela, passando pelo Lookahead Buffer e em seguida pelo dicionário, à medida que são codificados. Apenas existe compressão caso o número de bits usados para representar o token seja menor que o número de bits da sequência em causa. Os tokens de três componentes são ineficientes para a codificação de sequências de 1 e 2 caracteres.
Após a codificação do token a janela deslizante é deslocada n símbolos (sendo n a dimensão da sequência de caracteres encontrada) e são lidos n símbolos para o Lookahead Buffer, repetindo-se de seguida o processo anterior.
Existem alguns factores determinantes nas variantes do LZ77 que se reflectem num compromisso entre a memória, o tempo e a eficiência de compressão (a dimensão do dicionário, a dimensão do Lookahead Buffer e o tipo de parsing). O tipo de parsing determina, quando se encontra mais do que uma sequência repetida, qual das sequências é utilizada na codificação da informação que está no início do Lookahead Buffer. O tempo de codificação pode ser elevado caso o dicionário seja de dimensão elevada e o algoritmo de pesquisa tenha requisitos exigentes em relação à dimensão mínima da sequência a encontrar. Com o aumento da dimensão do dicionário aumenta-se a probabilidade de se encontrarem sequências (aumentando assim a eficiência de compressão mas também o tempo de processamento), com o aumento da dimensão do Lookahead Buffer pretende-se também aumentar a probabilidade de codificar sequências mais longas. Em cada passo de codificação tenta-se encontrar uma sequência existente no dicionário igual à que começa no início do Lookahead Buffer.
Algoritmo:
Input: sequência de símbolos, tamanho da janela W
Output: token na forma (P, T, C)
p ← N-F+1
Do while not EOF
Encontrar a maior sequência de símbolos existente no Lookahead Buffer coincidente com uma sequência existente no dicionário e a posição do primeiro símbolo dessa sequência no dicionário
Escreva o token (posição, tamanho, próximo símbolo no Lookahead Buffer)
p ← p + tamanho + 1
Descodificação
A descodificação LZ77 é mais simples e rápida que o codificador porque não requer pesquisa sobre o dicionário. O descodificador lê um token e verifica se existe coincidência, se esta existir o descodificador utiliza a posição e tamanho da sequência para fazer a reconstrução, senão imprime o símbolo presente no token.
Algoritmo:
Input: Token na forma (P, T, C)
Output: Sequência de símbolos
p ← N-F+1
Do while not EOF
Ler token (P, T, C)
Copiar T símbolos a partir da posição P do dicionário para o início do Lookahead Buffer
Copiar C para a posição seguinte do Lookahead Buffer
p ← p + T + 1
Exemplo de aplicação
Sequência a codificar: “bananabanabofana”
Ndic = 6 (comprimento do dicionário).
Nbuf = 4 (comprimento do buffer).
Codificação
1º Inicializa-se o buffer com os primeiros Nbuf símbolos da sequência a codificar. Inicialmente o dicionário não contém nenhum símbolo. Faz-se uma pesquisa pela maior sequência idêntica aos símbolos constantes do buffer na parte do dicionário, que como está vazio vai dar origem a um token de saída que indica deslocamento de ‘0’ posições, com tamanho ‘0’ e o símbolo seguinte não coincidente, que é ‘b’:
![]()
2º Desloca-se a janela tamanho+1 posições para a direita e volta a fazer-se a pesquisa e obtenção do token pela mesma forma:
![]()
3º Verifica-se a mesma situação anterior pois não foi encontrada nenhuma sequência:
![]()
4º Ao pesquisar, recuando 2 posições em relação ao inicio do buffer encontramos uma coincidência entre símbolos que se vai verificar nos 3 símbolos seguintes. Vai dar origem a token de saída que indica deslocamento de ‘2’ posições, com tamanho ‘3’ e o símbolo seguinte não coincidente, que é ‘b’:
![]()
5º Recuando 4 posições encontramos uma coincidência que se verifica nos 4 símbolos seguintes. Vai dar origem a um token de saída que indica deslocamento de ‘2’ posições, tamanho ‘3’ e o símbolo seguinte não coincidente, que é ‘o’:
![]()
6º Não encontramos coincidências, logo vai dar origem a token de saída que indica deslocamento de ‘0’ posições, tamanho ‘0’ e o símbolo seguinte não coincidente ‘f’:
![]()
7º Encontramos coincidência recuando 6 posições e durante os 3 símbolos seguintes. Dá origem a token indicando deslocamento de ‘6’ posições, tamanho ‘3’ e o próximo símbolo como é o final da sequência a codificar vai ser indicado como tal, a nulo.
![]()
8º Chegamos assim à codificação final da sequência de símbolos seguinte: (0,0,b),(0,0,a),(0,0,n),(2,3,b),(4,4,o),(0,0,f),(6,3,null).
Descodificação
Sequência de palavras de código: (0,0,b),(0,0,a),(0,0,n),(2,3,b),(4,4,o),(0,0,f),(6,3,null).
O processo de descodificação consiste em interpretar as palavras de código recebidas.
À medida que a sequência é formada serve de base para descodificar futuras palavras de código e a posição do apontador na iteração actual (Pi) vai avançando tamanho+1 posições.
|
Código |
Sequência descodificada |
|||||||||||||||
|
P1 |
P2 |
P3 |
P4 |
P5 |
P6 |
P7 |
||||||||||
|
(0,0,b) |
b |
|||||||||||||||
|
(0,0,a) |
b |
a |
||||||||||||||
|
(0,0,n) |
b |
a |
n |
|||||||||||||
|
(2,3,b) |
b |
a |
n |
a |
N |
a |
B |
|||||||||
|
(4,4,o) |
b |
a |
n |
a |
N |
a |
B |
a |
n |
a |
b |
o |
||||
|
(0,0,f) |
b |
a |
n |
a |
N |
a |
B |
a |
n |
a |
b |
o |
f |
|||
|
(6,3,null) |
b |
a |
n |
a |
N |
a |
B |
a |
n |
a |
b |
o |
f |
a |
n |
a |
Implementação do algoritmo LZ77
LZ77
Para implementar este algoritmo recorri a um array de tamanho WINDOW_SIZE, em representação da janela deslizante, o qual vai receber os primeiros BUFFER_SIZE símbolos a serem codificados e à medida que os vai codificando vai actualizar esse mesmo array movendo os símbolos constantes do array tamanho+1 posições para a esquerda, simulando assim o deslizamento da janela para a direita.
Para auxiliar na pesquisa da maior sequência possível de símbolos presente no dicionário, que corresponda a uma coincidência com os n primeiros símbolos do buffer, foi criada uma função que vai percorrer todo o dicionário e à medida que vai encontrando uma sequência mais longa coincidente com os símbolos constantes do buffer vai guardar a posição do primeiro símbolo coincidente e o tamanho da sequência, retornando no final esses mesmos valores num array de resultados, a serem utilizados para efectuar a construção do token de codificação a ser guardado num ficheiro.
Comparação com outros métodos semelhantes
A figura seguinte mostra comparação dos rácios de compressão entre os vários algoritmos baseados em dicionário da familia LZ77. Vários ficheiros foram usados para o teste:
- bib : lista de entradas bibliograficas(ASCII)
- book : livro de ficção(ASCII)
- geo : dados geofísicos (números 32 bits)
- obj : ficheiros executaveis para MAC e VAX
- paper : artigos científicos (ASCII)
- pic : imagem bitmap (preto/branco)
- term : sessão de terminal
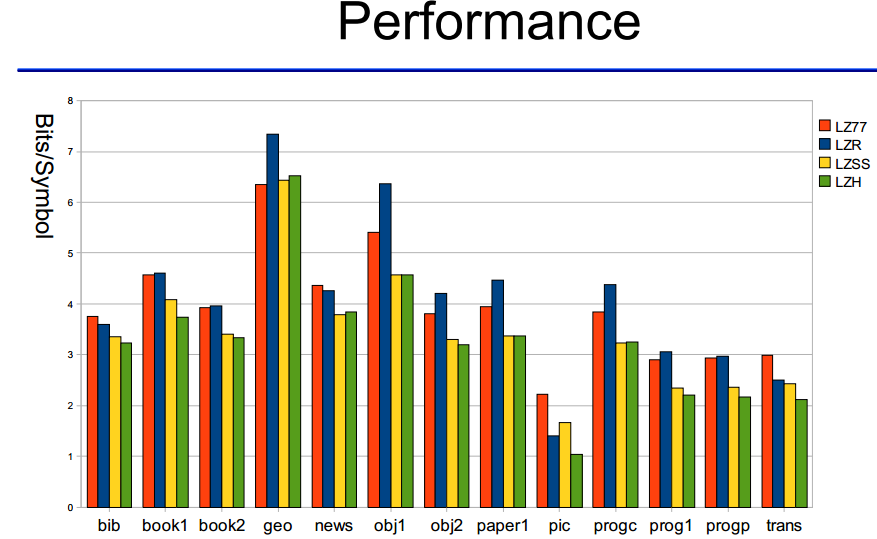
Imagem 4.1 – Comparação dos racios de compressão entre as diferentes variantes do LZ77
A figura seguinte mostra os vários algoritmos que derivaram do LZ77 e LZ78 com o objetivo de melhorar o desempenho destes algoritmos base.
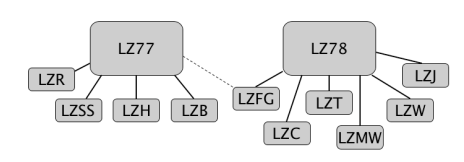
Imagem 4.2 – Familia de algoritmos LZ
A próxima imagem mostra uma comparação directa entre os melhores algoritmos da familia Lempel Ziv(LZB para LZ77 e LZFG para LZ78) e o algoritmo que alcançou os melhores resultados para codificação e Imagem 4.3 – Comparação LZ77/LZ78
Conclusão
O algoritmo LZ77 é um algoritmo simples e eficaz para comprimir texto/imagem e ao longo do tempo foi melhorado resultando assim os algoritmos LZB,LZSS e LZR mas mesmo assim continua a ser o mais utilizado devido a falta de patentes.LZ77 não é um dos algoritmos mais eficientes sendo que LZ78 e LZW conseguem obter rácios de compressão melhores mas como já foi referido devido a falta de patentes continua a ser muito utilizado na compressão de texto e imagem no formato PNG.O algoritmo tem restrições sendo que é possível utilizar o LZ77 apenas para comprimir ficheiros de texto e imagens no formato PNG. Não é possível comprimir áudio e vídeo.
Este método é assimétrico, demora mais tempo a codificar que a descodificar, pois para efectuar a codificação tem que fazer várias leituras dos símbolos na procura da maior sequência de símbolos passíveis de codificar com código já existente enquanto que na descodificação apenas faz a leitura do código e vai directamente à posição identificada por esse mesmo codigo copiar o símbolo já descodificado anteriormente.
O método é mais eficiente para codificação de textos longos, em que existem várias palavras que são repetidas constantemente mas também tem as suas desvantagens:
- A dimensão do dicionário condiciona até onde se pode pesquisar;
- A dimensão do lookahead buffer condiciona a máxima dimensão da sequência a codificar;
- Quanto maior a janela maior a compressão mas implica mais tempo de processamento e aumento do número de bits gastos nos componentes posição e tamanho;
- Pode ser desvantajoso codificar sequências de símbolos inferiores a 2 símbolos, pois o número de bits utilizados para codificar esses símbolos pode vir a ser mais elevado que os bits utilizados inicialmente por esses mesmos símbolos.
Bibliografia
[1] Christina Zeeh, “The Lempel Ziv Algorithm”, Seminar ”Famous Algorithms”, January 16, 2003.
[2] Ida Mengyi Pu, “Fundamental Data Compression”, 2006
[3] Guy E. Blelloch, “Introduction to Data Compression”, October 16, 2001.
Trabalho desenvolvido no âmbito da disciplina de Multimédia II da Licenciatura em Engenharia Informática, lecionada pelo Prof. Doutor Nuno Magalhães Ribeiro da Faculdade de Ciência e Tecnologia da UFP.
Texto da autoria de Gaspar Oliveira (21754) e revisto por Nuno Magalhães Ribeiro.
Código java da autoria de Gaspar Oliveira (21754).
Site planeado, desenhado, desenvolvido e programado por Daniel Dias Lima Mendes, Diogo Emanuel Lamas e Silva, Nelson José Santos Almeida no âmbito do Projeto de final de Licenciatura realizado na Unidade Curricular de Laboratório de Projeto Integrado sob a orientação técnica do Prof. Doutor Nuno Magalhães Ribeiro.