
Introdução
XMill – Compressor para dados no formato XML.
O compressor XMill é um compressor específico para dados no formato xml, que tipicamente alcança melhores taxas de compressão relativamente a outros compressores/métodos de compressão.
Particularmente na compressão de ficheiros de tamanho elevado(Mb), o uso do compressor XMill consegue alcançar taxas de compressão 2x superior às conseguidas utilizando o gzip.
Semelhante ao gzip o XMill é uma ferramenta de linha de comando que funciona numa base ficheiro-a-ficheiro. Dado um ficheiro com a extensão ‘.xml’, este é comprimido para um ficheiro com a extensão ‘.xmi’. Qualquer outro ficheiro sem a extensão ‘.xml’ é comprimido para um ficheiro onde é concatenada a extensão ‘.xm’.
Na descodificação do ficheiro, o original é obtido substituindo a extensão ‘.xmi’ pela extensão ‘.xml’, ou removendo a extensão ‘.xm’.
O XMill é um compressor sem perda, desenvolvido por Harmut Liefke[1] e por Dan Suciu[2]; o projecto XMill já não é mais mantido pelos seus criadores.
Áreas de aplicação
O XMill é um compressor destinado à compressão de dados no formato xml.
O xml é um formato desenvolvido com o intuito de tornar standard a comunicação entre aplicações.
O desenvolver de técnicas para codificar ficheiros no formato xml assume especial importância, pois um crescente numero de aplicações interpretam e conseguem gerar dados no formato xml. O xml é um protocolo comum que as mais diversas aplicações implementam e utilizam.
Sob o ponto de vista da performance de uma rede de computadores o fluxo gerado pela transferência de dados no formato xml pode tornar-se significativo pois aos dados originais, juntam-se ainda os relativos á especificação xml, ou seja , o overhead(<tags>).
De forma a optimizar então a transferência deste dados o recurso a um compressor é fundamental, é aqui o centro da actuação do XMill.
As taxas de compressão alcançáveis pelo XMill permitem optimizar a transferência de ficheiros no formato xml e o seu armazenamento(backup).
O algoritmo do “XMill”
O XMill explora uma estratégia em que agrupa e comprime os dados baseado na semântica destes. Por exemplo, uma sequência de elementos do tipo <Pessoa> com elementos(<Nome>, <Idade>, <Data Nascimento>, …) dentro de um documento xml podem ser rearranjados agrupando todos os nomes, todas as idades, e todas as datas de Nascimento juntas. Tipicamente este arranjo conduzirá a uma maior taxa de compressão, uma vez que cada grupo contém itens de texto com elevada similaridade.
A estratégia por defeito do XMill consiste em considerar uma ‘parent label’ no texto.
Embora funcional, esta técnica possui lacunas pois determinada label pode ter diferentes significados em diferentes partes do documento (exemplo: <Titulo> no interior de um elemento <Pessoa> possui um diferente significado do que <Titulo> no interior de um elemento <Livro>); outro caso pode ocorrer quando diferentes labels possuem o mesmo significado (exemplo: <Nome Criança> no interior de um elemento <Pessoa> possui o mesmo significado que a label <Nome>).
O XMill proporciona uma linguagem ‘regular path expression’[3] para agrupar os elementos de um texto respeitando o seu significado relativo ao elemento(xml) em que está inserido. Cada item do texto é alcançável através de um caminho de labels desde o nó de raiz do documento xml.
Por exemplo, o número de segurança social de um funcionário(<Funcionario>) de uma companhia(<Companhia>) pode estar armazenado no atributo ’ssnum’ de um elemento ‘<Raiz>’. Desta forma o caminho para o atributo ‘ssnum’ é o seguinte: /Raiz/Companhia/Funcionário/@ssnum.
Os atributos na expressão regular do XMill são precedidos do carácter ‘@’.
Após agrupar em contentores, é aplicado a cada um destes um compressor convencional como por exemplo o gzip; este irá explorar as similaridades entre os dados presente em cada contentor.
Uma vez que o número e tamanho dos contentores cresce com o tamanho do ficheiro xml, o XMill implementa um mecanismo de janela de memória que funciona do seguinte modo: quando o tamanho dos contentores previstos por defeito, atinge um certo tamanho janela de memória especificado pelo utilizador, os contentores são comprimidos e guardados no ficheiro de saída. O conteúdo comprimido da
janela de memória é chamado uma ‘run’. Após uma ‘run’ ser guardada no ficheiro de saída, os contentores são novamente preenchidos com dados.
O XMill prevê também a introdução de instruções sobre como efectuar uma “pré-compressão” sobre itens específicos no texto. Como exemplo desta funcionalidade, o utilizador pode substituir a representação dos dados na label <Idade> pela respectiva representação em binário. Desta forma, a instrução do utilizador proporciona uma maior compressão, através da representação dos mesmos dados com um menor número de bits.
Alguns métodos de compressão previstos pelo XMill ao utilizador são:
- Codificação diferencial para inteiros com sinal
- Compressão utilizando técnicas baseadas em dicionários
- Compressão utilizando técnicas run-lengh encoding
[1] Harmut Liefke, BMW Group, Munich, Germany,
[2] Dan Suciu, University of Washington, Seattle, USA,AT&T Labs
[3] String contem uma expressão regular que mapeia dados no documento.

Compressores semânticos atómicos presentes no XMill
Codificação
A Compressão é efectuada com base nas tags XML e o produto final recorre á utilização do gzip, de compressores específicos e de compressores user-defined.
- Separar a estrutura dos dados: A estrutura, constituída por tags e atributos XML, é comprimida separadamente dos dados, que consistem numa sequência de itens de dados (strings) representando conteúdos de elementos e valores de atributos.
- Agrupar itens de dados relacionados: Os itens de dados são agrupados em contentores, e cada contentor é comprimido separadamente. Por exemplo, todos os itens de dados <name> juntos formam um contentor, enquanto todos os itens de dados <telefone> juntos formam um segundo contentor.
- Aplicar compressores semânticos: Alguns itens de dados são números ou texto, enquanto outros podem ser por exemplo sequências de DNA. O XMill aplica compressores especializados (compressores semânticos) a contentores diferentes.
As tags e os atributos, que formam a estrutura XML, são enviados para o contentor de estrutura (structure container). Os valores de dados são enviados para vários contentores de dados, de acordo com as expressões de contentor (container expressions) e os contentores são comprimidos independentemente uns dos outros.
Arquitectura:
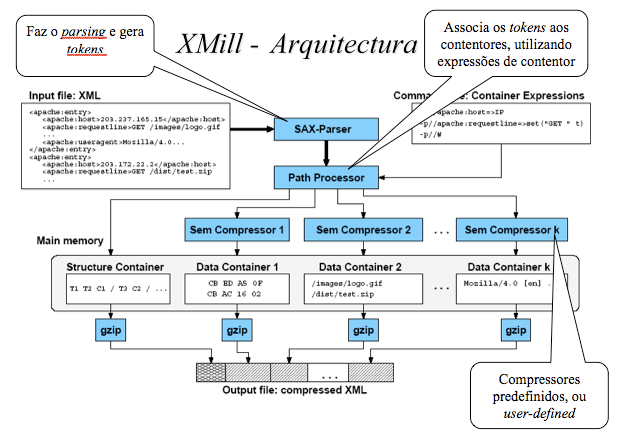
Arquitectura do compressor
As tags de início são codificadas usando o método de dicionário, ou seja, atribuindo-lhes um valor inteiro, enquanto todas as tags de fim são substituídas pelo token /. Os valores de dados são substituídos pelo número do seu contentor.
Obs: Os contentores mostrados na imagem começam em C2, porque o contentor C1 armazena a estrutura.
Na prática, todos os tokens são codificados como inteiros (com 1, 2 ou 4 bytes): as tags e os atributos são inteiros positivos, /(raiz) é 0 e os números dos contentores são inteiros negativos.
Sugestão do algoritmo de codificação em pseudo-código
while(!EOF) read xml file call function feed sax parser function feed sax parser pass data through sax parser separate structure from data if user defined pre-compressores aply user defined pre-compressores fill containers apply gzip compression to each container aplly huffman encoding to compressed file
Descodificação
A descodificação de um ficheiro compactado pelo XMill é realizado pelo descodificador XDemill, produto da autoria dos mesmos autores do XMill.
O processo de descodificação segue o caminho inverso do codificador.
É aplicado um descodificador de entropia Huffman, é aplicado o gunzip ao ficheiro, é interpretada a expressão regular produzida pelo codificador para mapear como reconstruir a informação original.
Através da expressão regular é possível reconstruir o xml através da consulta ao dicionário.
Exemplo de aplicação
Como é comprimida a estrutura do documento xml?
Exemplo:
<book>
<chapter></chapter>
<chapter><section/><section/><section/></chapter>
<chapter><section/><section/></chapter>
</book>
resulta na seguinte expressão:
0 1 / 12 / 2 / 2 / / 12 / 2 / / / (tag de fecho ‘/’)
e a seguinte tabela de símbolos:
[“book”,”chapter”,”section”]
0 1 2
A expressão e a tabela de símbolos são comprimidas por um compressor gzip.
Codificação
Estrutura do documento xml a codificar:
<book>
<chapter></chapter>
<chapter><section/><section/><section/></chapter>
<chapter><section/><section/></chapter>
</book>
Aqui a estrutura já se encontra separada dos dados(informação), e o algoritmo vai definir a path expression desde o nó de raiz(<book>) e criar um dicionário :
Raiz ->0
nova label aberta desconhecida->1
fecho label aberta ->/
abertura label conhecida->1
nova label aberta desconhecida->2
fecho label aberta ->/
abertura label conhecida->2
fecho label aberta ->/
abertura label conhecida->2
fecho label aberta ->/
fecho label aberta ->/
abertura label conhecida->1
abertura label conhecida->2
fecho label aberta ->/
abertura label conhecida->2
fecho label aberta ->/
fecho label aberta ->/
fecho label aberta ->/
Dicionário:
| Key | Value |
| 0 | <book> |
| 1 | <chapter> |
| 2 | <section> |
Em conjunto com a definição da path expression é também construído um dicionário. A construção da path expression consulta o dicionário para ver se a label que está a tratar já consta no dicionário ou se é uma nova entrada. No caso de nova entrada, incrementa o índice no dicionário e adiciona o valor da label.
Estes dados são colocados num contentor e comprimidos no gzip.
É importante destacar o aumento da performance do XMill, quando o utilizador conhece a os dados presentes na informação a codificar; pois pode indicar ao XMill a aplicação de diferentes técnicas de compressão a dados como um pré-processamento, melhorando o rácio de compressão.
Descodificação
Exemplo sobre a descodificação da estrutura:
Path expression: 0 1 / 12 / 2 / 2 / / 12 / 2 / / /
Dicionário:
| Key | Value |
| 0 | <book> |
| 1 | <chapter> |
| 2 | <section> |
<book>
<chapter></chapter>
<chapter><section/><section/><section/></chapter>
<chapter><section/><section/></chapter>
</book>
A descodificação consome um tempo de processamento aproximadamente ao do gunzip.
Comparação com outros métodos semelhantes

Gráfico comparativo da performance gzip/XMill
Linha de commandos relativo ao XMill:
Sem agrupamento (xmill //), agrupamento com base na tag pai (xmill //#) e agrupamento definido pelo utilizador com compressão semântica (abreviado como xmill <u>). No xmill <u> foi utilizada a melhor combinação de expressões de contentor que foi encontrada, para cada conjunto de dados.
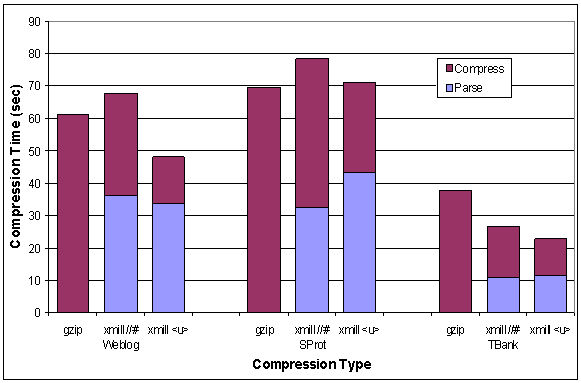
Gráfico que permite a observação em que o XMill consome mais tempo no processo de compressão a efectuar o parsing do documento xml, comparativamente á compressão dos dados xml.
O tempo de execução do XMill é aproximadamente o mesmo que o gzip
Principais desvantagens do XMill:
- ficheiro comprimido do XMill não permite a execução de querys. Para tal efeito o ficheiro tem que ser descomprimido.
- Requer intervenção humana de forma para a introdução de uma path expression que optimize o seu comportamento.
Conclusão
O codec XMill é um produto de baixa complexidade, que assenta basicamente num técnica de agrupamento de dados do ficheiro xml a tratar.
Por agrupar dados da mesma natureza em contentores de memória e comprimi-los separadamente explora da melhor forma compressores como o gzip, compressor por defeito no XMill.
O uso do XMill é atractivo para a circulação de dados xml em significante volume, especialmente em redes com pouca largura de banda, devido á compressão que proporciona.
De uma forma geral o XMill:
- Não é aconselhável para ficheiros pequenos (<20KB)
- Alcança melhores taxas de compressão que o gzip (com um factor de 2 para XML com mais dados que texto e menos caso contrário)
- Vocacionado para a compressão e transferência de dados na rede.
Melhora significativamente os tempos de transferência, principalmente em redes lentas.
Bibliografia
Erik Ray, T., “Learning XML”, O´Reilly, 1th. Edition, 2001
Jones ,C., “”,Python & XML, O´Reilly, 1th. Edition, 2002
McLaughlin, B “Java and XML”, O´Reilly, 2th. Edition, 2001
Scott Means, W., Rusty Harold E., “XML in a Nutshell”, O´Reilly, 2th. Edition, 2002
Sítio web[em linha] http://www.liefke.com/hartmut/xmill/xmill.html, Consultado em 1 Fevereiro 2009
Sítio web[em linha] http://sourceforge.net/projects/xmill, Consultado em 1 Fevereiro 2009
Sítio web[em linha]http://docs.python.org/library/xml.sax.html, Consultado em 3 Fevereiro 2009
Sítio web[em linha]http://docs.python.org/library/xml.dom.html, Consultado em 3 Fevereiro 2009
Sítio web[em linha]http://www.saxproject.org/, Consultado em 12 Fevereiro 2009
Sítio web[em linha]http://www.xmlsoft.org/, Consultado em 19 Fevereiro 2009
Sítio web[em linha]http://www.w3.org/XML/, Consultado em 10 Março 2009
Sítio web[em linha]http://www.jdom.org/downloads/docs.html, Consultado em 23 Março 2009
Sítio web[em linha] http://www.cs.washington.edu/homes/suciu/XMILL/, Consultado em 22 Abril 2009 [1]
[1] Apontador fornecido pelo autor Dan Suciu, após pedido de informação meu via e-mail
Trabalho desenvolvido no âmbito da disciplina de Multimédia II da Licenciatura em Engenharia Informática, lecionada pelo Prof. Doutor Nuno Magalhães Ribeiro da Faculdade de Ciência e Tecnologia da UFP.
Texto da autoria de Arthur Portas (16400) e revisto por Nuno Magalhães Ribeiro.
Site planeado, desenhado, desenvolvido e programado por Daniel Dias Lima Mendes, Diogo Emanuel Lamas e Silva, Nelson José Santos Almeida no âmbito do Projeto de final de Licenciatura realizado na Unidade Curricular de Laboratório de Projeto Integrado sob a orientação técnica do Prof. Doutor Nuno Magalhães Ribeiro.