
Introdução
O método de compressão “Move-to-Front” foi desenvolvido por Bentley, Sleator, Tarjan e Wei, em 1986, com o intuito de melhorar a performance da codificação de entropia para técnicas de compressão.
A Transformada Move-to-Front refere-se a um modo de compressão sem perdas (CSP).
Este modo de compressão ou codificação é totalmente reversível, a informação original é recuperada na totalidade e o efeito obtido e uma optimização da representação da informação. Este codec utiliza a técnica da codificação de entropia (Entropy Encoding). As técnicas de compressão referem-se a forma como os algoritmos encaram ou consideram a informação original a comprimir, sendo que, nesta técnica, a informação a comprimir é encarada como uma sequência de símbolos genéricos.
Áreas de aplicação
Sendo este método um método de compressão sem perdas, e usado em casos onde e importante que a informação original e a informação descomprimida sejam idênticas ou onde os seus desvios sejam ignoráveis. Este codec pode ser usado para imagens medicas, pois a perda de informação pode comprometer o diagnostico medico, sendo portanto mais apropriada a utilização de compressores sem perdas, onde toda a informação e preservada permitindo a recuperação perfeita da mensagem original.
O algoritmo da Transformada “Move-to-Front”
Este método consiste em codificar (codificação) uma string substituindo cada símbolo com a sua posição respectiva no array. Em cada substituição, será realocada a posição desse símbolo no array, sendo este movido para o início do mesmo. Assim, no final, os símbolos que foram mais recentemente usados, estarão no início do array.
Para a descodificação o processo é semelhante, dada uma sequência de símbolos codificada, e substituído cada valor pelo seu símbolo/carácter da respectiva posição do array. Assim como na codificação, em cada iteração será movido o respectivo carácter para o início do array.
Codificação
Dada uma string (conjunto de caracteres), cada um dos caracteres vai ser codificado, da esquerda para a direita. Existe inicialmente uma lista que, por convenção, vai ser o alfabeto (‘a’ a ‘z’, com índices de 0 a 25), que vai determinar o índice de cada um dos caracteres da string. Começando, então, pelo primeiro carácter que esta mais a esquerda na string, vai ser procurada a sua posição na lista do alfabeto, que vai determinar o seu índice. Dando como output o índice desse carácter, a lista, para procurar o índice do segundo carácter já vai ser diferente, pois vai ter como índice 0 o carácter que foi procurado anteriormente, pois o caracter será sempre movido para o início da lista. Este processo repete-se ate ao final da string.
Portanto, o output será uma sequência de índices de todos os caracteres/símbolos da string.
Algoritmo de codificação em pseudo-codigo:
Encode() {
Alfabeto "abcdefghijklmnopqrstuvwxyz";
Para i=0 ate palavra.length {
Para j=0 ate alfabeto.length {
Se palavra[i] == alfabeto[j] {
Finalcode[i] = j;
Mover alfabeto[j] para alfabeto[0];
}
j++;
}
i++;
}
Return finalcode;
}
Descodificação
Dada um conjunto de dígitos, separados por “,”, cada um dos dígitos vai ser descodificado, da esquerda para a direita. Existe inicialmente uma lista que, por convenção, vai ser o alfabeto (‘a’ a ‘z’, com índices de 0 a 25), que vai determinar qual o caracter correspondente a cada um dos dígitos a descodificar. Começando, então, pelo primeiro digito que está mais à esquerda, vai ser procurada a sua posição na lista do alfabeto, que vai determinar o seu caracter. Dando como output o caracter desse dígito, a lista, para procurar o caracter do segundo dígito já vai ser diferente, pois vai ter como índice 0 o carácter que foi descodificado do dígito anterior, pois o caracter será sempre movido para o início da lista. Este processo repete-se até ao final do conjunto de dígitos.
Portanto, o output será uma sequência de caracteres de todos os índices a descodificar.
Algoritmo de descodificação em pseudo-codigo:
Decode () {
Alfabeto "abcdefghijklmnopqrstuvwxyz";
Para i=0 ate digitos.length {
Finalcode[i] = alfabeto[dígitos[i]];
Mover alfabeto[dígitos[i]] para alfabeto[0];
i++;
}
Return finalcode;
}
Exemplo de aplicação
Nesta secção vamos usar como exemplo a palavra “universidade” para demonstrar o funcionamento do algoritmo de codificação e descodificação da transformada “Move-to-Front”. Serão explicados, detalhadamente, todos os passos dos algoritmos até ao resultado final.
Codificação
A tabela que vamos apresentar, contém três variáveis, o input que corresponde a todos os caracteres da variável de entrada; o output que corresponde a codificação dos respectivos caracteres, e a symbol table (tabela de símbolos) que corresponde ao alfabeto que vai servir para determinar o índice de cada um dos caracteres obtendo-se o respectivo output.
Na primeira iteração, o input e o output encontram-se vazios e a symbol table apresenta o alfabeto de ‘a’ a ‘z’.
No segundo passo, o input vai conter o caracter ‘u’ da palavra “universidade” que vai ter como referência para a sua codificação o alfabeto inicial, procurando o seu índice e apresentando-o no output. De seguida quando se obtém o output, o carácter do alfabeto correspondente ao da nossa string vai ser colocado no índice 0.
Cada um destes passos vão ser repetidos para os restantes caracteres da string pretendida, sendo que o alfabeto usado para a codificação de cada um deles será o que obtém no índice 0 o carácter anterior ao actual que esta a ser codificado. No final teremos o output da string, que vai corresponder aos índices de cada um dos caracteres, estando assim a codificação finalizada.
De seguida apresentamos a tabela para demonstrar, de uma forma prática, cada um dos passos que aqui foram explicados:
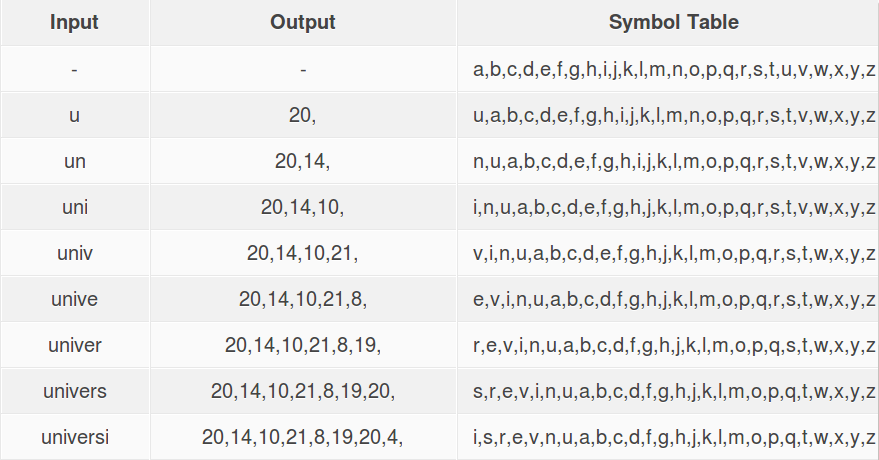
Input: “universidade”
Output final: 20, 14, 10, 21, 8, 19, 20, 4, 10, 8, 1, 5
Descodificação
Pegando agora na forma comprimida do exemplo obtido na secção anterior, da palavra “universidade” conseguimos obter a sua descodificação.
A tabela que vamos apresentar, contem três variáveis, o input que corresponde a todos os dígitos da variável de entrada; o output que corresponde a descodificação dos respectivos dígitos, e a symbol table (tabela de símbolos) que corresponde ao alfabeto que vai servir para determinar o índice de cada um dos caracteres obtendo-se o respectivo output.
Na primeira iteração, o input e o output encontram-se vazios e a symbol table apresenta o alfabeto de ‘a’ a ‘z’.
No segundo passo, o input vai conter o primeiro dígito, “20”, que vai ter como referência para a sua descodificação o alfabeto inicial, procurando o seu índice e apresentando o respectivo caracter no output. De seguida quando se obtém o output, o carácter do alfabeto correspondente ao digito que foi descodificado, vai ser colocado no índice 0.
Cada um destes passos vão ser repetidos para os restantes dígitos, sendo que o alfabeto usado para a descodificação de cada um deles será o que obtém no índice 0 o carácter anterior ao actual dígito que esta a ser descodificado. No final teremos o output, que vai corresponder aos caracteres de cada um dos dígitos, estando assim a descodificação finalizada.
De seguida apresentamos a tabela para demonstrar, de uma forma prática, cada um dos passos que aqui foram explicados:
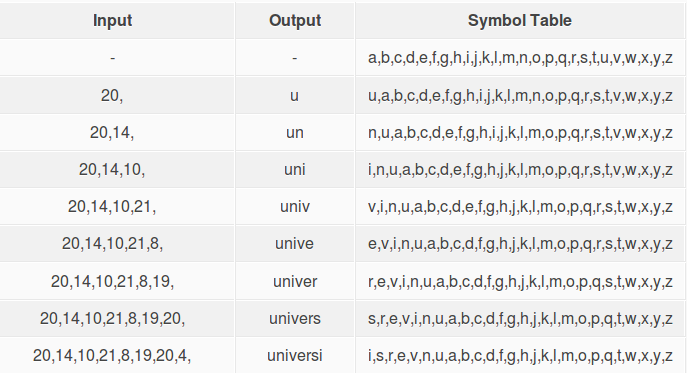
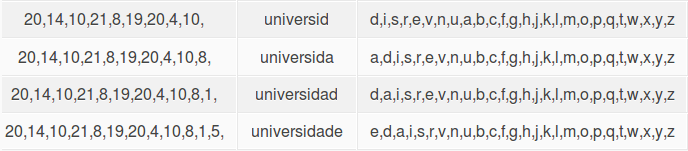
Input: 20, 14, 10, 21, 8, 19, 20, 4, 10, 8, 1, 5
Output final: “universidade”
Implementação do algoritmo “Move-to-Front”
Para a implementação do algoritmo de codificação, foi necessário percorrer a palavra que e dada como input, bem como o alfabeto, de ‘a’ a ‘z’, da tabela de símbolos. De seguida verificou-se se o caracter a tratar, da palavra, correspondia ao caracter do alfabeto. Caso isso se verificasse, guardou-se o respectivo índice no nosso final code (output). Por fim, colocou-se esse caracter no índice 0 do alfabeto.
Para a implementação do algoritmo de descodificação, foi necessário percorrer os dígitos dados no input e verificar a que caracter do alfabeto corresponde cada um dos dígitos, guardando cada um deles numa variável para o output. Por fim, colocou-se o caracter no índice 0 do alfabeto.
A linguagem utilizada para o desenvolvimento dos algoritmos foi a linguagem JavaScript, com auxílio de bibliotecas JQuery, CSS e HTML.
Algoritmo de codificação:
var encode = function (palavra){
var strSymbol=[];
for(var i=0; i<palavra.length; i++) {
strSymbol[i] = new Array(palavra.length);
}
$('.output').empty();
var x;
var b = {charList: "abcdefghijklmnopqrstuvwxyz".split('')};
var finalcode = [];
var i,j,k;
palavra = palavra.toLowerCase();
for(j = 0; j < palavra.length; j++){
for(i = 0; i < b.charList.length; i++){
if(palavra[j] == b.charList[i]){
finalcode[j] = i;
b.charList.splice(i, 1)[0];
b.charList.splice(0,0,palavra[j]);
}
}
strSymbol[j] = b.charList.slice(0);
console.log(b.charList);
}
createTable(palavra, finalcode, strSymbol);
};
Algoritmo de descodificação:
var decode = function (numList) {
var strSymbol=[];
for(var i=0; i<numList.length; i++) {
strSymbol[i] = new Array(numList.length);
}
var abc = {alfabeto: "abcdefghijklmnopqrstuvwxyz".split('')};
var word = [];
var aux = numList.split(",");
for(i=0; i<aux.length; i++){
word.push(abc.alfabeto[aux[i]]);
abc.alfabeto.splice(0, 0, (abc.alfabeto.splice(aux[i], 1)[0]));
strSymbol[i] = abc.alfabeto.slice(0);
}
createTable(numList, word, strSymbol);
};
Transformada Move-to-Front em javascript
Comparação com outros métodos semelhantes
É possível comparar o método de codificação e descodificação da transformada Move-to-Front com outros métodos semelhantes, tais como o método de Codificação Diferencial.
Sendo a Transformada Move-to-Front um método usado como pré-processamento para baixar a entropia, é possível compará-lo com a Codificação Diferencial pois este método tem esta mesma finalidade como seu princípio de funcionamento.
Pegando no exemplo visto anteriormente, da palavra “universidade”, para a transformada Move-to-Front, o seu débito binário será:
Debito binário = comprimento do input × nº bits por símbolo
Debito binário = 12 caracteres × 8 bits = 96 bits/símbolo
E o rácio será:
Rácio = comprimento do input × nº bits por símbolo / comprimento do output × nº bits de cada código de saída
Rácio = (((97 + 100 + 101 + 105 + 110 + 114 + 115 + 117 + 118) / 12) × 8) /
(12 × 12) = 4,52
Pegando no mesmo exemplo para a Codificação Diferencial:
| Amostra | ASCII | Δ | Nº bits |
| a | 97 | 97 – 0 = 97 | 7 |
| d | 100 | 100 – 97 = 3 | 2 |
| e | 101 | 101 – 100 = 1 | 0 |
| i | 105 | 105 – 101 = 4 | 2 |
| n | 110 | 110 – 105 = 5 | 3 |
| r | 114 | 114 – 110 = 4 | 2 |
| s | 115 | 115 – 114 = 1 | 0 |
| u | 117 | 117 – 115 = 2 | 1 |
| v | 118 | 118 – 117 = 1 | 0 |
| Total = 17 | |||
Rácio = 9 × 8 bits / 17 bits = 4,24
Conclusão
O método analisado trata-se de um método de baixa complexidade, visto que ambos os seus algoritmos de codificação e descodificação são de fácil compreensão, bem como toda a parte do rastreio que envolve codificar ou descodificar um conjunto de caracteres (no caso da codificação) ou dígitos (no caso da descodificação). Em termos de desempenho, o seu pior caso resulta quando os caracteres/dígitos são todos diferentes e encontram-se no fim do alfabeto, de forma decrescente de “z” a “a”, obrigando o algoritmo a percorrer todos os caracteres do alfabeto ate encontrar o correspondente ao do seu input, e o seu melhor caso, quando os caracteres/dígitos são todos iguais.
Tratando-se de um método usado como pré-processamento, foi possível compará-lo com a Codificação Diferencial, um método que é, também, usado como pré-processamento. Como podemos concluir, como estes métodos são usados para a mesma finalidade, produzem rácios de compressão semelhantes, mas através dos cálculos realizados anteriormente, conclui-se, portanto, que a Codificação Diferencial é mais eficiente, pois produz um rácio de compressão inferior ao da Transformada Move-to-Front.
Os aspectos que consideramos ser os mais importantes são os procedimentos para “resolver” a codificação e descodificação de uma dada string de input, bem como a implementação de ambos os algoritmos. As áreas de implementação deste método são, também, igualmente importantes, visto que ajudam a perceber que, tratando-se de um método de compressão sem perdas, é importante usá-lo em diversas áreas, em que seja importante obter a informação preservada.
Bibliografia
Salomon, D., “Data Compression”, Springer, 4th. Edition, 2002.
Wikipedia. Move-to-Front transform. 23 de Novembro de 2015. https://en.wikipedia.org/wiki/Move-to-front_transform.
Algorithm. https://rosettacode.org/wiki/Move-to-front_algorithm#JavaScript.
“Transformada Move-to-Front.” 2016. http://multimedia.ufp.pt/codecs/compressao-sem-perdas/supressao-de-sequencias-repetitivas/transformada-move-to-front/.
Blelloch, Guy E., “Introduction to Data Compression”, 16 de Outubro de 2001.
Pu, Ida M., “Fundamental Data Compression”, 2006.
“Move-to-front algorithm.” 21 de Janeiro de 2008. http://www.cim.mcgill.ca/~langer/423/lecture8.pdf.
Implementação do algoritmo em JAVA Move-to-Front
Trabalho desenvolvido no âmbito da disciplina de Multimédia II da Licenciatura em Engenharia Informática, lecionada pelo Prof. Doutor Nuno Magalhães Ribeiro da Faculdade de Ciência e Tecnologia da UFP.
Texto da autoria de A, B e C e revisto por Nuno Magalhães Ribeiro.
Código javascript da autoria de Ana Costa (29666), Luís Pascoal (29335) e Rui Braga (30191)
Código java da autoria de Bruno, Daniel e Rui Coelho.
Site planeado, desenhado, desenvolvido e programado por Daniel Dias Lima Mendes, Diogo Emanuel Lamas e Silva, Nelson José Santos Almeida no âmbito do Projeto de final de Licenciatura realizado na Unidade Curricular de Laboratório de Projeto Integrado sob a orientação técnica do Prof. Doutor Nuno Magalhães Ribeiro.